- AI with Armand
- Posts
- The Future of AI is in Inference
Welcome to the 210 new members this week! This newsletter now has 44,655 subscribers.
The future of AI is undoubtedly headed towards inference-centric workloads. While the training of LLMs and other complex AI models gets a lot of attention, inference makes up the vast majority of actual AI workloads.
Today, I’ll cover:
What is Model Inference?
How AI Inference Works
Challenges of Model Inference
AI at the edge
External vs. In-House AI Infrastructure
Let’s Dive In! 🤿
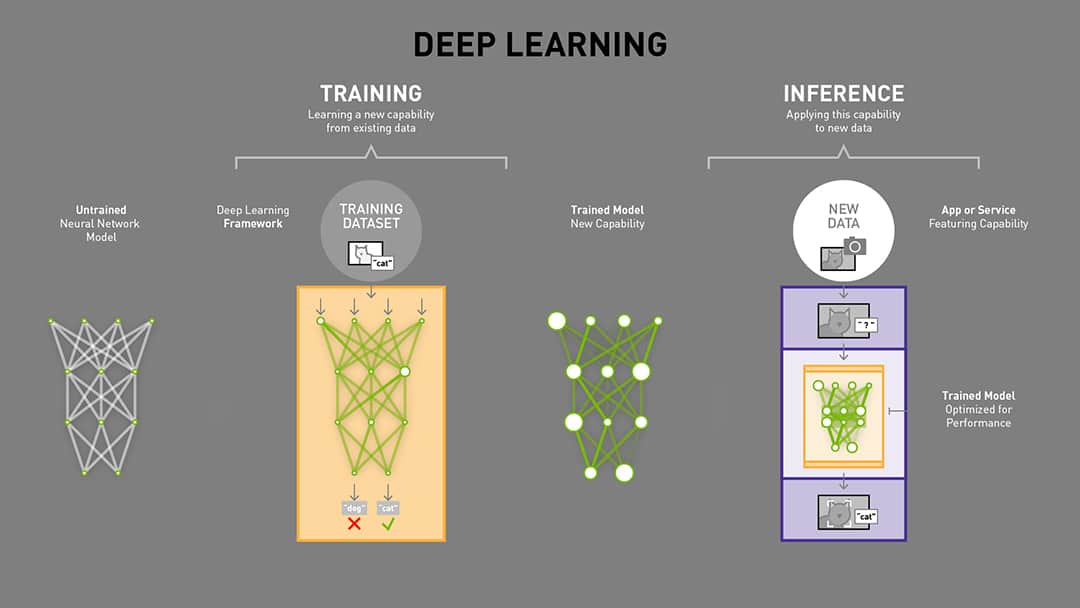
What is Model Inference?
While training large, complex AI models often hogs the spotlight, inference is the real workhorse of AI deployments. But what exactly is model inference, and how does it differ from the training process?
At a high level, inference refers to using a pre-trained AI model to make predictions or decisions on new, unseen data. During the training phase, the model "learns" patterns and relationships in a large dataset, developing an internal representation of the problem it's trying to solve.
Once the training is complete and the model's performance has been validated, it can be deployed to make real-world predictions. This deployment phase is known as inference. The model takes in new data inputs, processes them through its learned internal representations, and outputs a prediction or decision.
Here’s an example:
Imagine a computer vision model trained to identify different types of animals in images. During the training phase, the model may have been exposed to millions of labeled animal images, learning to recognize the visual patterns and features that distinguish a dog from a cat or a giraffe from a zebra.
Once this training is complete, the model can be used for inference - shown a new, previously unseen image and tasked with identifying the type of animal present. The model will apply the knowledge it gained during training to analyze the visual features of the new image and output a prediction, such as "This is a German shepherd."
The key difference between training and inference is that training is a resource-intensive, one-time process of building the model's capabilities. In contrast, inference is the model's ongoing, day-to-day usage to make real-time predictions and decisions. Inference is often orders of magnitude more common than the original training workload.
How AI Inference Works
So, how exactly does this inference process work under the hood? There are a few key technical steps involved:
Data Preprocessing: When new input data is fed into the AI model, it often needs to be preprocessed and transformed into a format the model can understand. This might involve resizing or normalizing images, tokenizing and embedding text, or extracting relevant features from raw sensor data.
Model Execution: The preprocessed data is passed through the trained AI model. Depending on the model architecture, this may involve feeding the data through multiple layers of artificial neurons, with each layer performing some transformation or feature extraction.
Output Generation: The final layer of the model will generate the actual output prediction or decision. This could be a classification label, a numeric value, or a complex structured output like a generated sentence or image.
Post-processing: In some cases, the raw model output may need additional post-processing to make it suitable for the end-use case. This could involve rounding numeric predictions, applying probability thresholds, or formatting the output into a specific data structure.
The key thing to understand is that this inference process is highly optimized and streamlined compared to the training phase. Inference workloads are designed to be fast, efficient, and scalable, since they represent the AI system's core "production" usage.
How Model Inference works - credits of image to Nvidia Blog
The ML model is hosted in an infrastructure where the model can run. It will expect input data in a specific format and produce certain outputs, usually predictions with a confidence score.
For example, let's say you're running a website and want to show different ads to different users based on their interests. You could use a machine learning model to predict each user's interests based on their browsing behavior on your website (data that you collect about their clicks, pages visited, etc.). You could then use these predictions to show users ads that are relevant to their interests. This process—collecting data, making predictions, and taking action based on those predictions—is known as "inference."
Challenges of Model Inference
While inference may be more straightforward than the training process, it still comes with its own unique set of challenges that organizations need to navigate:
Performance & Latency: Inference workloads must be extremely performant, often operating under tight latency requirements. Slow or inconsistent inference can render an AI system unusable, especially for time-sensitive applications like self-driving cars or industrial automation.
Resource Efficiency: Inference may not be as compute-intensive as training, but it still requires significant hardware resources like GPUs, specialized AI chips, and high-bandwidth memory. Minimizing the resource footprint of inference is crucial for cost-effectiveness and energy efficiency.
Model Management: Deploying and managing AI models in production environments is complex. Organizations need robust versioning, monitoring, and update processes to ensure that models remain accurate and compliant.
Security & Privacy: The distributed, data-intensive nature of inference workloads creates new security and privacy challenges. Safeguards are needed to protect sensitive data and prevent malicious actors from exploiting vulnerabilities in deployed AI systems.
Explainability & Transparency: As AI systems become more sophisticated, there is growing demand for them to be interpretable and explainable. Providing visibility into how inference models arrive at their outputs is an important but challenging area.
Navigating these inference-specific challenges is critical to realizing the full business value of AI investments. Organizations that can master the art of efficient, scalable, and trustworthy inference will be well-positioned to lead in the era of AI-powered transformation.
AI at the edge
Traditionally, the inference is done on central servers in the cloud. However, recent advancements in edge computing are making it possible to do model inference on devices at the network's edge. That is critical for some use cases, like in self-driving cars.
Deploying models on devices at the edge has several advantages. First, it reduces latency because data does not have to be sent to the cloud for processing. Second, it conserves bandwidth because only the results of the inference need to be transmitted rather than the entire dataset. Third, it can provide better privacy protection since sensitive data never leaves the device.

Where is the money? Source: Source: McKinsey and Co.
External vs. In-House AI Infrastructure
As organizations look to deploy more inference-centric AI, they face a key strategic decision: should they build their own internal AI infrastructure or leverage external cloud/edge AI services?
There are pros and cons to each approach:
Building In-House Infrastructure:
Maintain full control over the AI stack and deployment environment
Customize hardware, software, and processes to specific needs
Potentially lower long-term costs for high-volume inference workloads
Requires significant upfront investment and ongoing IT resources
Using External AI Services:
Faster time-to-value with pre-built, managed AI services
Offload infrastructure management and scaling to the provider
Access to the latest AI hardware and software innovations
Ongoing subscription costs may be higher long-term
Ultimately, the decision will depend on factors like the scale and criticality of the inference workloads, the organization's technical capabilities, and the availability of suitable external AI services. Many enterprises are opting for a hybrid approach, using external providers for certain inference needs while building in-house solutions for mission-critical or high-volume use cases.
Wrapping up
The future of AI is undoubtedly centered around inference workloads, which comprise the vast majority of real-world AI computing demands. As enterprises grapple with the challenges of deploying and managing efficient, secure, and scalable inference, a few key trends emerge:
How will AI infrastructure cost evolve?
The exponential growth in model parameters and GPU compute power seen in recent years may start to slow, as training data sizes and hardware improvements hit practical limits.
However, the continued growth of the overall AI industry and developer community will likely sustain high demand for powerful AI infrastructure, preventing any significant cost declines in the near future.
The high upfront costs of building large-scale AI models could create a "moat" that makes it difficult for new entrants to catch up to well-funded incumbents. However, open-source initiatives have shown the market remains dynamic and quickly evolving.
Ultimately, the trajectory of AI infrastructure costs will be a crucial factor shaping the future competitive landscape. Organizations that can navigate the complexities of efficient, secure, and scalable inference will be well-positioned to lead the charge as AI becomes increasingly pervasive across industries.
Think about Inference in your next AI Project!
AI inference is a vital part of AI. If you're running a business, understanding how inference works can help you make better decisions about using AI to improve your products and services. And if you're interested in pursuing a career in AI, developing strong inference skills will be critical.
and that’s all for today. Enjoy the weekend, folks.
Armand
Whenever you're ready, learn AI with me:
The 15-day Generative AI course: Join my 15-day Generative AI email course, and learn with just 5 minutes a day. You'll receive concise daily lessons focused on practical business applications. It is perfect for quickly learning and applying core AI concepts. 15,000+ Business Professionals are already learning with it.
Reply